数据结构汇总
作者:wallace-lai
发布:2024-06-22
更新:2024-06-22
堆
【pending】
数组
【pending】
链表
【pending】
并查集
(1)建立集合
#define MAX_NODE_SUM (128)
static unsigned sum;
static int pa[MAX_NODE_SUM];
void uf_init(unsigned n)
{
assert(n <= MAX_NODE_SUM);
sum = n;
for (int i = 0; i < n; i++) {
pa[i] = i;
}
}
(2)查找根结点
首先写一个没有路径压缩的版本如下:
int uf_find0(int x)
{
assert(x < sum);
// no compress
while (x != pa[x]) {
x = pa[x];
}
return x;
}
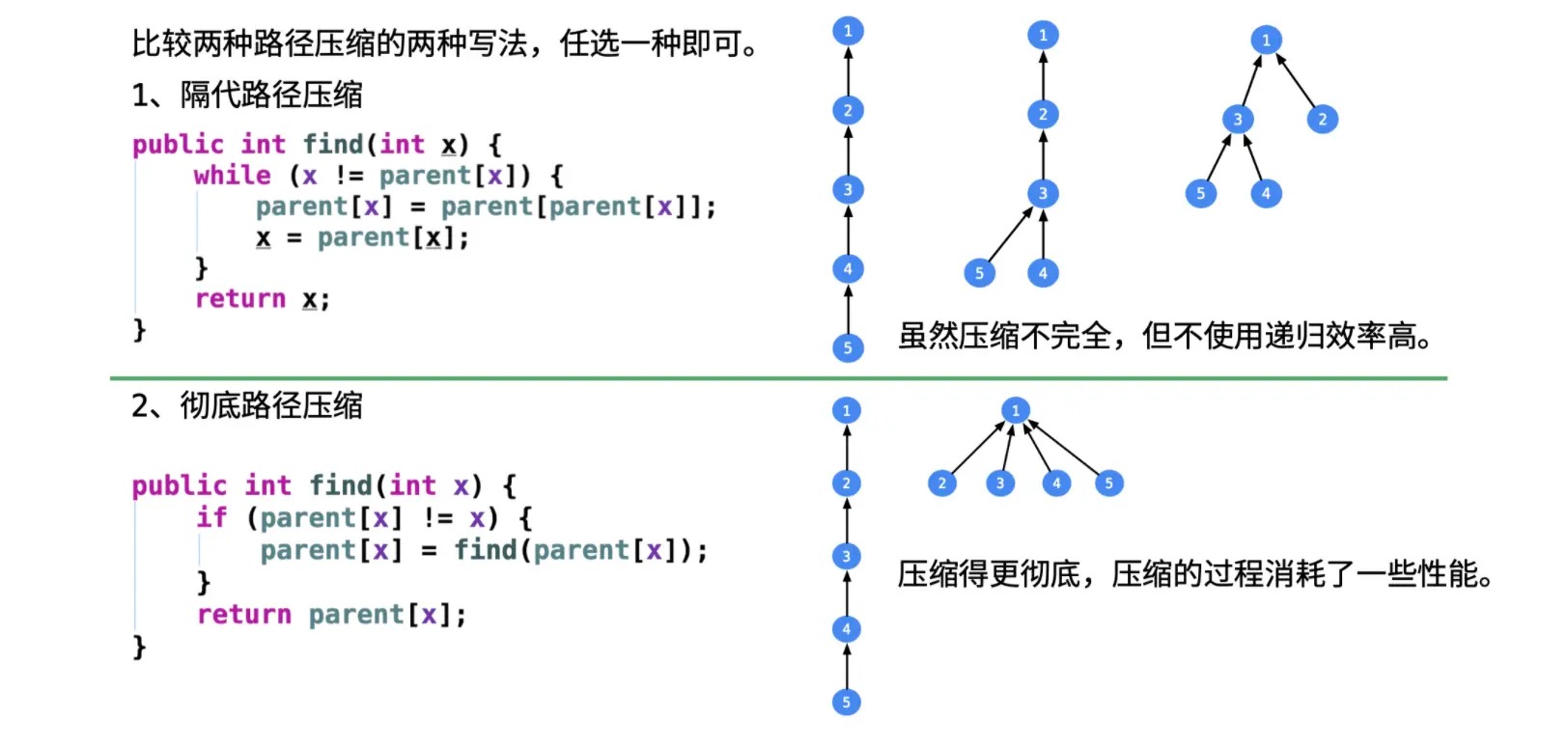
如下图所示,假设要查找结点5的根结点,则uf_find0的将沿着5 -> 4 -> 3 -> 2 -> 1的路径找到结点5所归属的根结点为1。
图片来源:leetcode题解
什么是隔代路径压缩?核心思想是每当发现结点x不是最终的根结点时,则将结点x的父结点设置为结点x父节点的父节点。此时结点x就与其父结点处于同一层次,结点x和其父结点由上下层父子关系变成了同层级的兄弟关系,缩短了查询路径。重复这一过程,直至遇到最终的根结点为止。
隔代路径压缩代码实现如下所示:
int uf_find1(int x)
{
assert(x < sum);
// compress
while (x != pa[x]) {
pa[x] = pa[pa[x]];
x = pa[x];
}
return x;
}
什么是完全路径压缩?核心思想是每当发现结点x不是最终根结点时,则将其根结点设置为其父结点的根结点,同时对其父结点递归地进行相同的操作。重复这一过程,最终所有搜索路径上的非根节点的父节点都将被设置成最终的根结点。
完全路径压缩代码实现如下所示:
int uf_find2(int x)
{
assert(x < sum);
// full compress
if (x != pa[x]) {
pa[x] = uf_find2(pa[x]);
}
return pa[x];
}
针对find(5)的递归调用形式如下:
pa[5] = find(pa[5])
= find(4)
pa[4] = find(pa[4])
= find(3)
pa[3] = find(pa[3])
= find(2)
pa[2] = find(pa[2])
= find(1) // find(1) == 1
pa[2] = 1 // return find(1)
pa[3] = 1 // return pa[2]
pa[4] = 1 // return pa[3]
pa[5] = 1 // return pa[4]
(3)合并两个节点
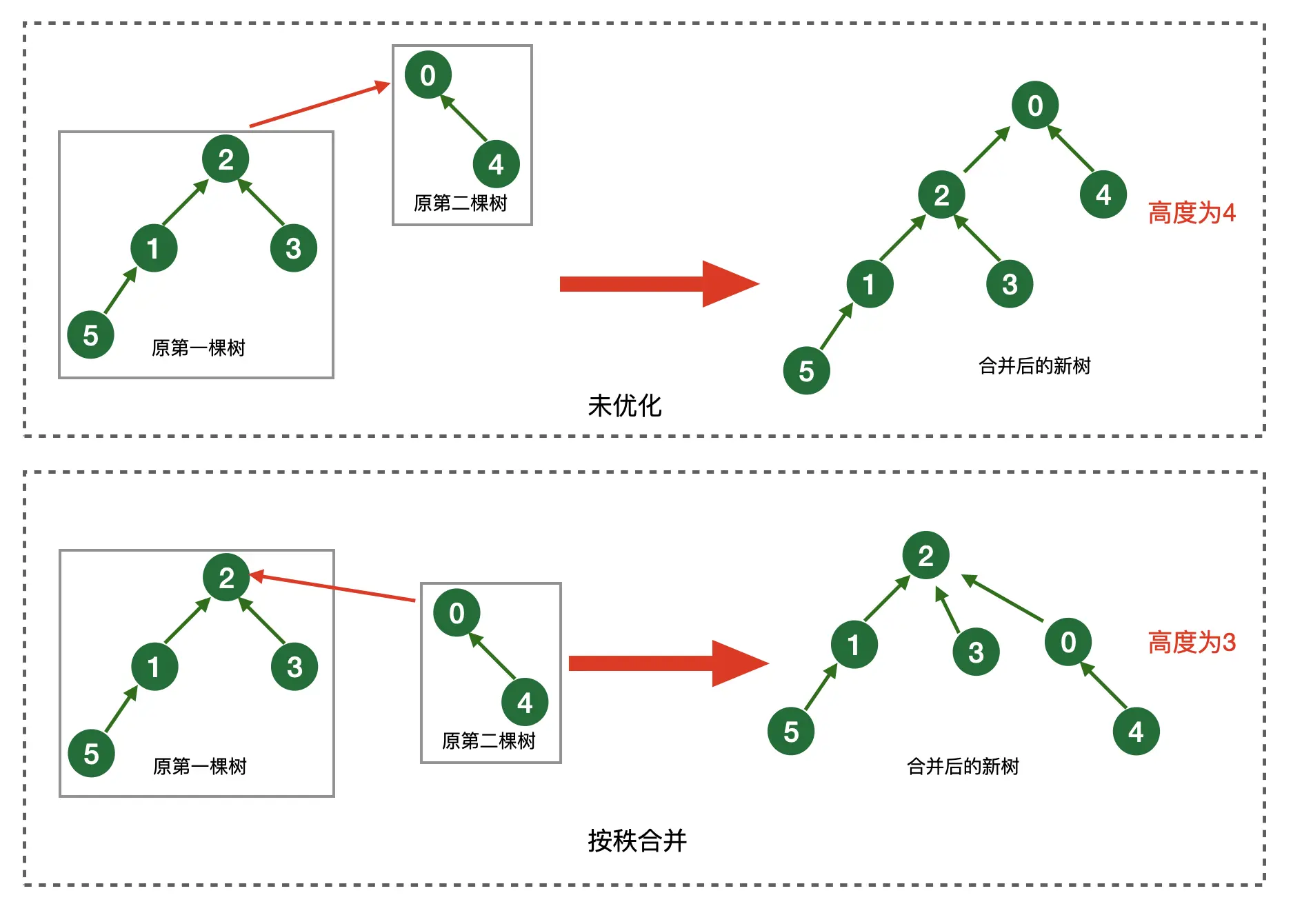
首先写一个不带任何优化的版本如下,核心思想是找到两个结点x和y的最终根结点,如果两个根结点不相等说明两个结点x和y位于不同的子树中,将结点x的最终根结点的父节点设置为结点y的最终父结点。这相当于是将结点x所在的子树挂在了结点y所在的子树下,两棵树合并成了一棵树。
图片来源:leetcode题解
typedef int (*uf_find_ptr)(int x);
int uf_union(int x, int y)
{
uf_find_ptr uf_find = uf_find0;
int xp = uf_find(x);
int yp = uf_find(y);
if (xp != yp) {
pa[xp] = yp;
}
}
对于并查集的两结点合并,有个优化方法叫做按秩合并,即将秩(树结点个数)少的树合并到另一个秩更大的树上。目的是为了降低合并后树的高度。但是,你在查找的时候就会做路径压缩,感觉合并做的这点优化有点不痛不痒。更何况为了实现按秩合并,需要维护每个树结点所包含的子树个数,即ranks数组,这需要增加一些内存和时间成本。
因此对按秩合并不做描述,需要的话可以查阅相关资料。
栈与队列
栈
(1)声明:stack<int> stk;
(2)入栈:stk.push(1)
(3)出栈:stk.pop()
注意:若栈为空,则pop()会抛异常
(4)取栈顶元素:stk.top()
(5)判空:stk.empty()
(6)栈中元素个数:stk.size()
队列
(1)声明:queue<int> q;
(2)入队:q.push(x);
(3)出队:q.pop();
(4)返回队首元素:q.front()
(5)返回队尾元素:q.back()
(6)判空:q.empty()
(7)返回队列个数:q.size()
双端队列
(1)声明:deque<int> dq
(2)队尾插入:dq.push_back(1)
(3)队首插入:dq.push_front(1)
(4)队尾删除:dq.pop_back()
(5)队首删除:dq.pop_front()
(6)返回队尾元素:dq.back()
(7)返回队首元素:dq.front()
(8)返回(修改)第i个元素:dq.at(i)
(9)遍历队列:
for (deque<int>::iterator it = dq.begin(); it != dq.end(); it++) {
// ...
}
(10)判空:dq.empty()
(11)返回队列个数:dq.size()
优先队列
【pending】
二叉树
二叉树的解题模式有两大类:
(1)遍历思维:通过遍历一遍二叉树配合外部变量记录来实现;
(2)分解思维:定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案;
二叉树的遍历框架:
void Traverse(TreeNode *root)
{
if (root == nullptr) {
return;
}
// 前序位置
Traverse(root->left);
// 中序位置
Traverse(root->right);
// 后续位置
}
前序位置:前序位置的代码在刚刚进入一个二叉树结点的时候执行;
后序位置:后序位置的代码在即将要离开一个二叉树结点的时候执行;
中序位置:中序位置的代码在一个二叉树结点左子树都遍历完毕,即将开始遍历右子树的时候执行
将这两个概念扩展到数组和指针:
// 迭代遍历数组
void Traverse(vector<int> &arr)
{
for (int i = 0; i < arr.size(); i++) {
// do something
}
}
// 递归遍历数组
void Traverse(vector<int> &arr, int i)
{
if (i == arr.size()) {
return;
}
// 前序位置
Traverse(arr, i + 1);
// 后序位置
}
struct ListNode {
int val;
ListNode *next;
};
// 迭代遍历
void Traverse(ListNode *head)
{
for (ListNode *p = head; p != nullptr; p = p->next) {
// do something
}
}
// 递归遍历
void Traverse(ListNode *head)
{
if (head == nullptr) {
return;
}
// 前序位置
Traverse(head->next);
// 后序位置
}
二叉树的层序遍历:
void LevelOrderTraverse(TreeNode *root)
{
if (root == nullptr) {
return;
}
queue<TreeNode *> q;
q.push(root);
while (!q.empty()) {
TreeNode *curr = q.front();
q.pop();
// do something on curr
if (curr->left != nullptr) {
q.push(curr->left);
}
if (curr->right != nullptr) {
q.push(curr->right);
}
}
}
如果需要通过层序遍历获知二叉树的深度,可以这么做:
void LevelOrderTraverse(TreeNode *root)
{
if (root == nullptr) {
return;
}
queue<TreeNode *> q;
q.push(root);
int depth = 1;
while (!q.empty()) {
int size = q.size();
for (int i = 0; i < size; i++) {
TreeNode *curr = q.front();
q.pop();
// do something on curr
if (curr->left != nullptr) {
q.push(curr->left);
}
if (curr->right != nullptr) {
q.push(curr->right);
}
}
depth++;
}
}